TechOps

Scheduled jobs that actually run — and tell us when they don't
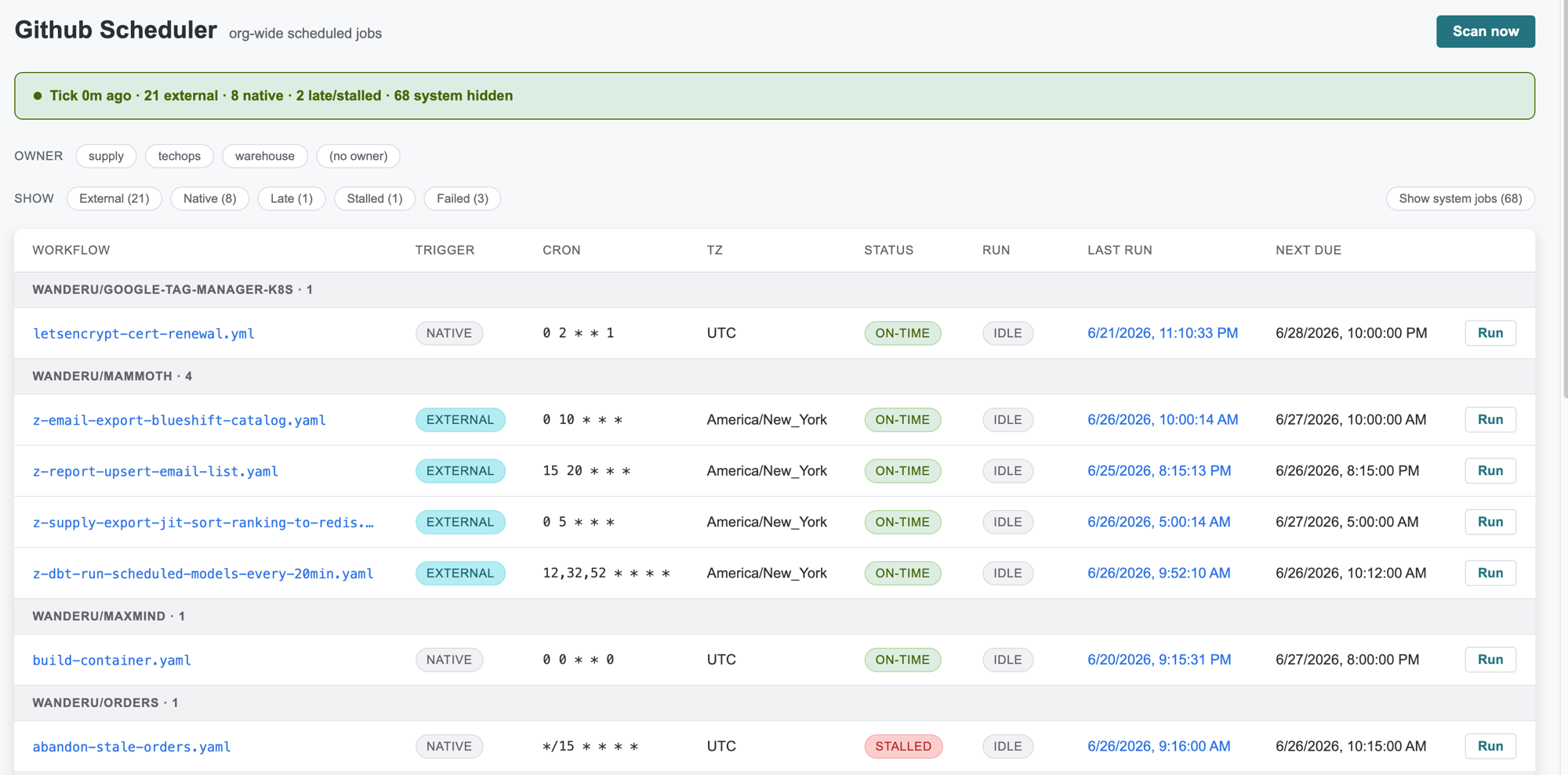
Org-wide scheduled jobs — owner, status, drift, and one-click run.
Query the warehouse from anywhere — even your phone

Asking the warehouse from the Claude mobile app.
@Claude in Slack, grounded in our knowledge
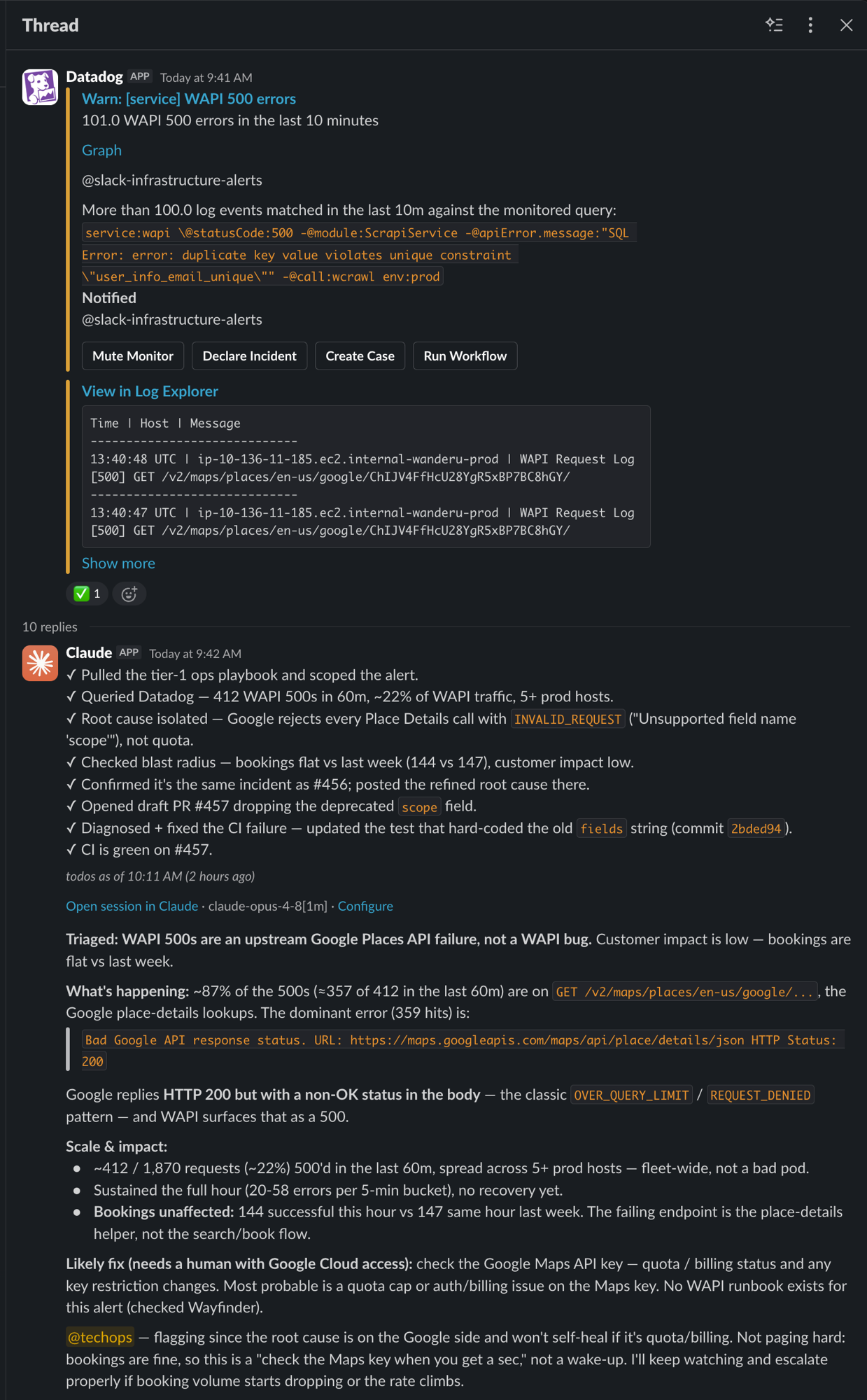
Triaging a Datadog WAPI alert in-thread — root cause, draft fix, and a heads-up to #techops.